

There are two key concepts to measuring the resilience of an uninterruptible power supply: Reliability covers the ability of the UPS to perform its necessary functions under stated operating conditions for a specified period of time. Availability focuses on whether a UPS is operational when required for use and takes into account both system running time and downtime.
Several metrics help to measure UPS resilience, although a certain element of caution is advised. Firstly, UPS configuration can have a direct impact on resilience and availability i.e. a parallel-redundant installation can achieve higher availability than a single UPS.
There’s also no universally accepted standard with most of the widely-used metrics, leading to competing UPS manufacturers having differing favoured approaches to measurement. This makes accurate comparisons tricky.
Finally, there are factors outside the manufacturer’s control. For example, UPS systems installed in temperature-controlled, highly regulated environments are less likely to experience faults and failures than units faced with extremes in heat, cold, vibration and dust.
Mean Time To Repair (MTTR)
Mean Time To Repair (MTTR) measures the average time it takes to repair a UPS and restore it to full operating functionality following a failure. Also known as Mean Time To Restore or Mean Time To Recover, it is calculated by dividing the total maintenance time by the total number of maintenance actions over a set period of time.
It’s extremely unlikely a UPS service engineer will happen to be onsite at the moment a UPS system fails. That’s why MTTR should factor in the time it takes for an engineer to arrive on site to produce an accurate figure.
Some UPS manufacturers will only base their MTTR figure based on the actual repair time. A truly comprehensive MTTR should measure the entire time from which the failure is first discovered through to when the UPS returns to full working operation.
Mean Time Between Failures (MTBF)
Mean Time Between Failures (MTBF) measures the average length of operational time between powering up a UPS and system shutdown caused by a failure. It predicts the time (usually in hours) that passes between one UPS system breakdown and the next and is calculated by dividing the total operational time by the number of failures.
MTBF is incumbent on the presumption that the equipment will fail at some point. It doesn’t take into account when a UPS is voluntarily shut down for preventive maintenance or routine parts replacement. Instead, MTBF only focuses on failures that require a UPS to be taken out of operation in order for it to be repaired.
Naturally, failure rates aren’t constant. UPS systems mirror other sensitive electronic devices by following what’s known as the ‘Bathtub Curve’, which outlines three distinct periods ‘A’, ‘B’ and ‘C’:
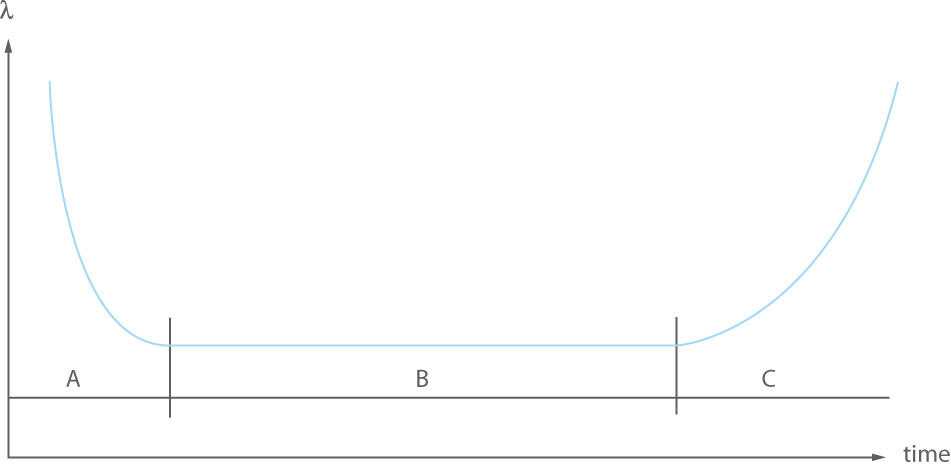
- Period A – ‘Infant Mortality’ failures: corresponds to early failures caused by a component or manufacturing defect or transportation problem.
- Period B – ‘Random’ failures: during the normal working life of a UPS the rate of these failures is normally low and fairly constant.
- Period C – ‘Wear Out’ failures: towards the end of working life, system failure rates increase significantly.
Be aware that while MTBF is an indication of reliability and availability, it does not represent the expected service life of a UPS.
An online UPS has a typical MTBF of roughly 250,000 hours, although this will vary depending on the manufacturer. Note that when the UPS is in bypass mode and the load is connected to the mains, the MTBF of the system drops to that of the mains electricity supply.
Mean Time To Failure (MTTF)
Another, lesser-used, metric is Mean Time To Failure (MTTF). It measures the reliability of products and systems that cannot be repaired, and is comparable to MTBF, which is used in cases where repairing and returning to use is possible.
MTTF offers a reasonable indication of how long a product is expected to last until it fails. In other words, it provides an estimate of service life.
MTTF is calculated by dividing the total hours of operation by the number of products being tracked – most MTTF data is collected by running multiple products (often thousands) over an extended period of time to provide the most accurate possible figure.
Availability
Availability measures both system running time and downtime. It combines the MTBF and MTTR metrics to produce a result rated in ‘nines of availability’ using the formula: Availability = (1 – (MTTR/MTBF)) x 100%.
The greater the number of ‘nines’, the higher system availability. In mission-critical environments such as data centres, ‘5 nines’ and above is fast becoming the desired standard.
| Availability | Level | Downtime Per Year |
|---|---|---|
| 99.9999% | 6 nines | 32 seconds |
| 99.999% | 5 nines | 5 minutes 35 seconds |
| 99.99% | 4 nines | 52 minutes 33 seconds |
| 99.9% | 3 nines | 8 hours 46 minutes |
| 99% | 2 nines | 87 hours 36 minutes |
| 90% | 1 nine | 36 days 12 hours |